Q5
4) There is no question 4.1 or 4.2.
4.3) The main ingredient in Aqamed is a painkiller called paracetamol.
Figure 8 represents a molecule of paracetamol.
4.3) The main ingredient in Aqamed is a painkiller called paracetamol.
Figure 8 represents a molecule of paracetamol.
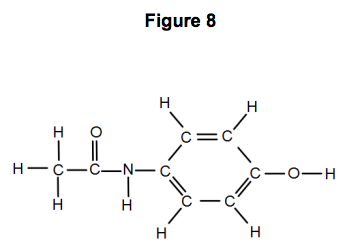
Give the molecular formula of paracetamol.
Calculate its relative formula mass (Mr).
Relative atomic masses (Ar): H = 1; C = 12; N = 14; O = 16 [2 marks]
Molecular formula _________________________________________
Relative formula mass _________________________________________
Calculate its relative formula mass (Mr).
Relative atomic masses (Ar): H = 1; C = 12; N = 14; O = 16 [2 marks]
Molecular formula _________________________________________
Relative formula mass _________________________________________
Mr = _________________________________________
Aspirin is a medicine for use by adults.
An aspirin tablet contains 300 mg of acetylsalicylic acid.
Calculate the number of moles of acetylsalicylic acid in one aspirin tablet.
Give your answer in standard form to three significant figures.
Relative formula mass (Mr) of aspirin = 180
[4 marks]
Number of moles = ____________________________
(Total for Question 4 = 9 marks)